基于LangGraph的Translation Agent 开发#
ReAct 模式#
现代智能体(如基于 LangChain 框架的 Agent)常采用“ReAct”风格设计,因为这种方式既结合了内在思考又能调用外部工具,还可以根据观察到的反馈不断改进最终答案。不同的应用场景可能会组合并调整这些模式,以满足特定任务的需求。
整个“思考–行动–观察”循环的流程如下:
思考(Thought)
分析用户输入,检索是否包含特殊术语。
决策:是直接翻译,还是先处理术语。
行动(Action)
构造调用翻译工具的命令,并传入原文和预定义术语(例如以 JSON 格式)。
执行翻译动作。
观察(Observation)
获取翻译工具返回的翻译结果作为反馈。
通过反馈对翻译效果进行验证。
更新思考并输出最终回答
根据反馈更新内在思考,确认翻译达到了预期效果。
生成最终回答并回复给用户。
基础准备#
本练习以千问大模型作为Agent的大脑。需要开通阿里云百炼的API。
翻译流程设定#
本部分主要是为了快速演示Agent的开发,而非设计完整而强大的 Translation Agent,因此只设计了最简单的流程。
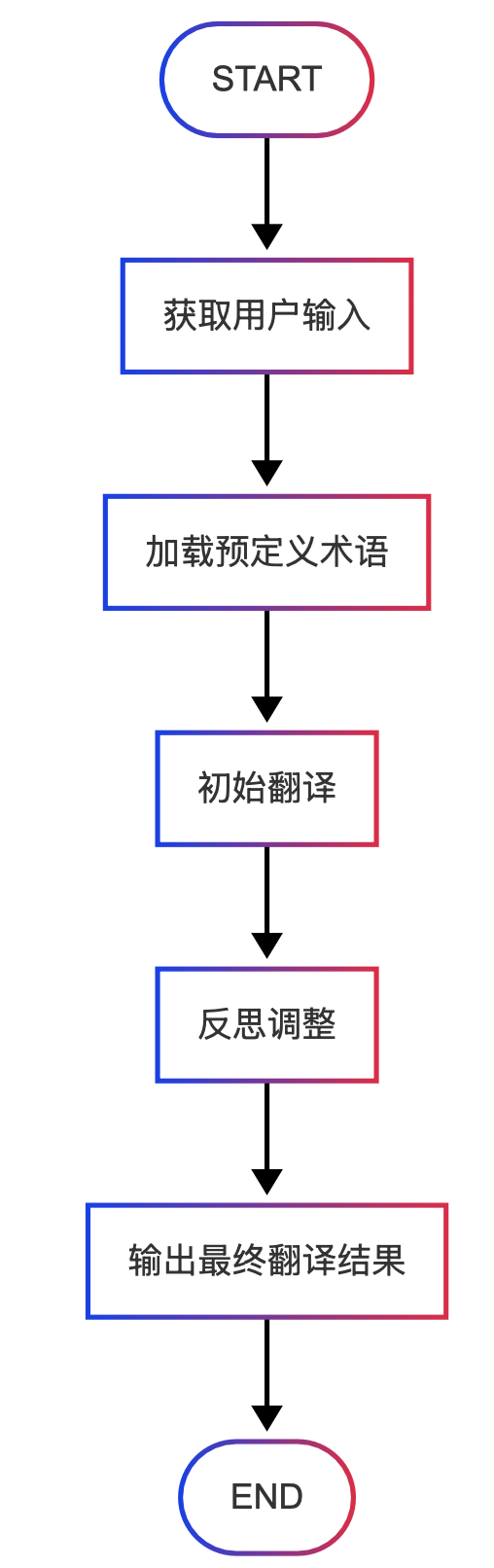
示例代码#
安装 LangGraph 和 langchain_openai
%pip install langgraph langchain_openai
导入所需库和模型初始化
from langgraph.graph import StateGraph, START, END from langchain.chat_models import ChatOpenAI from langchain_core.messages import HumanMessage from typing import TypedDict, Optional, Dict, Any, List import os # 初始化 LLM(此处示例为 Qwen,注意替换 API 参数) model = ChatOpenAI( temperature=0, model_name="qwen-plus", openai_api_key="you-api-key", openai_api_base="https://dashscope.aliyuncs.com/compatible-mode/v1", )
定义状态数据结构
class TranslationState(TypedDict): original_text: str # 待翻译的英文文本 glossary: Dict[str, str] # 预定义的术语翻译映射 final_translation: Optional[str] # 最终翻译结果 messages: List[Dict[str, Any]] # 与 LLM 交互的记录
节点0:获取用户输入
def get_user_input(state: TranslationState): user_text = input("请输入要翻译的文本:").strip() if not user_text: # 当检测不到输入时,采用默认文本 user_text = "Promts and Tokens are important concepts in the field of Large Lanuage Models." print("未检测到输入,默认使用示例文本。") return {"original_text": user_text}
节点1:加载预定义术语(这里直接内置,也可从文件加载)
def lookup_glossary(state: TranslationState): predefined_glossary = { "Promts": "提示词", "Token": "词元", "Large Langauge Model": "语言大模型" } print("预定义术语:", predefined_glossary) return {"glossary": predefined_glossary}
节点2:初始翻译 – 根据用户原文和预定义术语构造提示调用翻译工具
def translate_text(state: TranslationState): original_text = state.get("original_text", "") glossary = state.get("glossary", {}) # 构造提示:直接将全部预定义术语附加到提示中 prompt = f"请将下面的英文文本翻译成中文:\n\n{original_text}\n\n" if glossary: prompt += f"请注意,以下术语必须使用规定翻译:{glossary}\n" messages = [HumanMessage(content=prompt)] response = model.invoke(messages) initial_translation = response.content.strip() # 更新状态并记录交互历史 state["messages"].extend([ {"role": "user", "content": prompt}, {"role": "assistant", "content": initial_translation} ]) print("初始译文:", initial_translation) return {"final_translation": initial_translation}
节点3:反思调整 – 模拟“思考–行动–观察”循环,反复改进翻译结果
def refine_translation(state: TranslationState): max_iterations = 3 iteration = 0 current_translation = state.get("final_translation", "") # 进入迭代循环,每次生成新的改进方案 while iteration < max_iterations: # 修改思考提示: # 如果当前译文已足够好,请返回原译文,并在后面附加‘(已确认)’;否则,请给出详细改进后的译文。 thought_prompt = ( f"当前翻译为:\n{current_translation}\n\n" "作为一名专业翻译专家,请你分析这段译文是否存在不足;" "如果存在改进建议,请给出改进后的译文;" "如果你认为当前翻译已经足够准确,请在原译文后附加‘(已确认)’二字,并返回完整译文。" ) messages = [HumanMessage(content=thought_prompt)] response = model.invoke(messages) new_translation = response.content.strip() state["messages"].append({ "role": "assistant", "content": f"(Iteration {iteration+1}) {new_translation}" }) print(f"反思调整第 {iteration+1} 轮:", new_translation) # 如果返回结果中包含 "(已确认)",表示 LLM确认当前译文足够准确, # 我们就剥离标记并认为翻译结果最终稳定 if "(已确认)" in new_translation: # 去掉标记后作为最终译文 current_translation = new_translation.replace("(已确认)", "").strip() break # 如果改进后的译文与当前译文基本相同,也认为无需继续调整 if new_translation == current_translation or abs(len(new_translation) - len(current_translation)) < 5: break else: current_translation = new_translation iteration += 1 return {"final_translation": current_translation}
节点4:输出最终翻译结果
def finalize(state: TranslationState): print("\n=== 翻译任务完成 ===") print("最终翻译结果:") print(state.get("final_translation")) return {}
构建 LangGraph 流程图,将各节点按照顺序连接
translation_graph = StateGraph(TranslationState) translation_graph.add_node("get_user_input", get_user_input) translation_graph.add_node("lookup_glossary", lookup_glossary) translation_graph.add_node("translate_text", translate_text) translation_graph.add_node("refine_translation", refine_translation) translation_graph.add_node("finalize", finalize) translation_graph.add_edge(START, "get_user_input") translation_graph.add_edge("get_user_input", "lookup_glossary") translation_graph.add_edge("lookup_glossary", "translate_text") translation_graph.add_edge("translate_text", "refine_translation") translation_graph.add_edge("refine_translation", "finalize") translation_graph.add_edge("finalize", END) compiled_graph = translation_graph.compile()
初始化状态(注意:初始时 original_text、glossary 和翻译为空)
initial_state: TranslationState = { "original_text": "", "glossary": {}, "final_translation": None, "messages": [] }
运行
compiled_graph.invoke(initial_state)
输出结果:
预定义术语: {'Promts': '提示词', 'Token': '词元', 'Large Langauge Model': '语言大模型'}
初始译文: 提示词和词元是语言大模型领域中的重要概念。
反思调整第 1 轮: 提示词和词元是语言大模型领域中的重要概念。(已确认)
=== 翻译任务完成 ===
最终翻译结果:
提示词和词元是语言大模型领域中的重要概念。
{'original_text': 'Promts and Tokens are important concepts in the field of Large Lanuage Models.',
'glossary': {'Promts': '提示词', 'Token': '词元', 'Large Langauge Model': '语言大模型'},
'final_translation': '提示词和词元是语言大模型领域中的重要概念。',
'messages': [{'role': 'user',
'content': "请将下面的英文文本翻译成中文:\n\nPromts and Tokens are important concepts in the field of Large Lanuage Models.\n\n请注意,以下术语必须使用规定翻译:{'Promts': '提示词', 'Token': '词元', 'Large Langauge Model': '语言大模型'}\n"},
{'role': 'assistant', 'content': '提示词和词元是语言大模型领域中的重要概念。'},
{'role': 'assistant',
'content': '(Iteration 1) 提示词和词元是语言大模型领域中的重要概念。(已确认)'}]}