常见大模型评价指标#
随着大型语言模型(LLM)在自然语言处理(NLP)任务中的广泛应用,对其进行科学、全面的评估成为一项核心挑战。不同任务(如文本生成、翻译、问答、代码生成等)对模型的评价需求各异,因此,研究者们提出了多种评价指标。本节将介绍主要的LLM评价方法,并结合具体示例说明其适用场景、优缺点及应用实践。
评估维度#
模型评估一般从以下几个维度展开:
领域特定能力(Domain-Specific Capability):衡量模型在特定任务上的表现,如代码生成、医疗文本分析等。
生成能力(Generation Capability):评估文本生成的连贯性、准确性、信息完整性等。
指令遵循能力(Instruction-Following Capability):测试模型能否遵循用户指令,包括格式要求、内容约束等。
成本与延迟(Cost and Latency):计算API调用成本、推理速度,以优化部署策略。
通用评估方法#
对于非代码类的领域能力,通常使用封闭式任务(Close-ended Tasks)来评估,例如使用多选题(Multiple-Choice Questions, MCQs),封闭式输出更容易验证。
例如 MMLU benchmark中的一道题:
Question:#
One of the reasons that the government discourages and regulates monopolies is that
(A) Producer surplus is lost and consumer surplus is gained.
(B) Monopoly prices ensure productive efficiency but cost society allocative efficiency.
(C) Monopoly firms do not engage in significant research and development.
(D) Consumer surplus is lost with higher prices and lower levels of output.
Label: (D)
译文如下:
问题:
政府反对并监管垄断的一个原因是:
(A) 生产者剩余减少,而消费者剩余增加。 (B) 垄断定价确保生产效率,但损害社会的配置效率。 (C) 垄断企业不会进行重要的研发。 (D) 消费者剩余因价格上涨和产量下降而减少。
正确答案:D
语言建模指标#
困惑度(Perplexity, PPL)#
定义
困惑度(Perplexity)衡量模型对文本的预测能力,其计算公式如下:
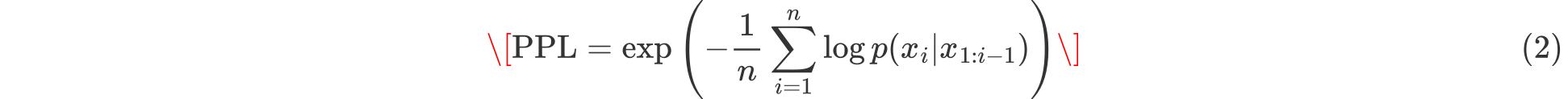
解释
数值越低,表示模型越擅长预测给定文本。
一般用于衡量自回归(Autoregressive)语言模型,如GPT系列的基础语言建模能力。
示例
假设有两个语言模型:
模型A对句子”The cat sat on the mat.” 预测的概率为 0.04
模型B预测相同句子的概率为 0.02
由于模型A的困惑度较低(数值越低表示预测越稳定),说明它比模型B更适合处理该文本。
优缺点
适用于评估语言模型的基本预测能力。
计算简单,适用于不同规模的训练数据集。
不能衡量文本的真实度或逻辑一致性,仅适用于评估语言流畅性。
在生成式任务(如开放域对话)中,低困惑度并不意味着输出高质量。
参考文本对比类指标#
这类指标主要用于评估机器翻译、摘要生成、文本改写等任务,通过对比模型生成的文本与参考文本之间的相似度进行评分。
BLEU(Bilingual Evaluation Understudy)#
定义
BLEU 衡量候选文本和参考文本的n-gram匹配度,公式如下:
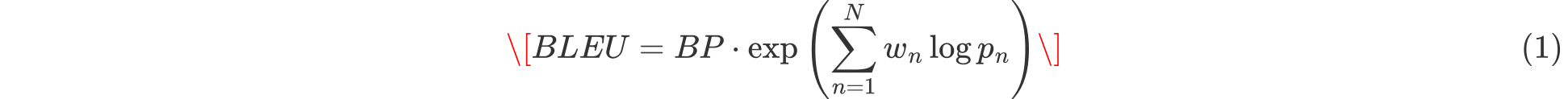
其中:
( BP ) 是长度惩罚因子,避免模型生成过短文本得高分。
( p_n ) 是 n-gram 精确匹配率。
示例 假设参考文本为:
“The quick brown fox jumps over the lazy dog.”
模型A生成:
“A fast brown fox leaps over a sleepy dog.”
BLEU-1(1-gram匹配):75%(单词匹配较好)
BLEU-2(2-gram匹配):40%(短语匹配较差)
优缺点
在机器翻译、文本改写等任务中有广泛应用。
计算高效,可用于模型对比。
不能衡量语义相似性,仅计算表面文本匹配。
对于自由度较高的生成任务(如开放式问答)效果较差。
ROUGE(Recall-Oriented Understudy for Gisting Evaluation)#
定义
ROUGE 主要用于摘要任务,衡量生成文本与参考文本之间的n-gram、最长公共子序列(LCS)等匹配情况。
常见变体
ROUGE-N(n-gram匹配):如 ROUGE-1, ROUGE-2。
ROUGE-L(最长公共子序列匹配)。
ROUGE-S(跳跃n-gram匹配)。
示例 假设参考摘要:
“AI models are becoming more powerful every year.”
模型生成:
“Each year, AI models grow stronger.”
ROUGE-1(单词匹配):80%
ROUGE-2(2-gram匹配):50%
ROUGE-L(LCS匹配):60%
优缺点
广泛应用于文本摘要任务。
适用于评估抽取式摘要质量。
不适用于自由度较高的生成任务,如创意写作。
对句法变化和同义词替换不敏感。
任务特定评价指标#
精确率(Precision)、召回率(Recall)和 F1 值#
用于分类任务(如情感分析、意图检测等)。
示例 假设进行垃圾邮件分类:
100 封邮件,其中 30 封是垃圾邮件。
模型预测了 35 封垃圾邮件,其中 25 封预测正确。
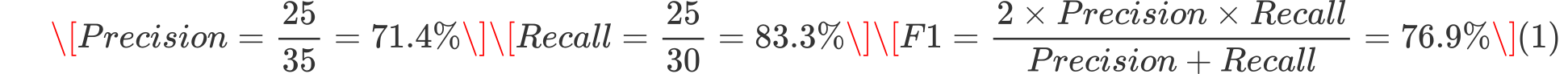
代码生成指标(Pass@k)#
定义
在代码生成任务中,Pass@k 衡量生成的前 k 个代码是否有至少一个能通过测试。
示例 假设模型生成 5 个候选代码:
代码 1 ❌(编译错误)
代码 2 ✅(通过测试)
代码 3 ❌(逻辑错误)
代码 4 ✅(通过测试)
代码 5 ❌(部分正确)
则:

优缺点
直接衡量代码可用性,真实反映开发环境。
依赖测试用例,覆盖不足可能导致低估/高估模型能力。
人工评价方式#
评分量表(Likert Scale)#
人工评分(如1-5级量表)用于评估文本流畅性、事实性、逻辑性。
排序对比(Pairwise Comparison)#
让评审员比较两个模型的输出,选择更优者。如:
GPT-4 vs. GPT-3.5 生成摘要,评审员选择更好的版本。
事实性与伦理评估#
LLM 可能产生幻觉(Hallucination)或偏见(Bias),需额外评估:
FactCC、QAGS:检测文本是否符合已知事实。
Perspective API:检测文本是否包含仇恨或有害内容。
总结#
不同任务需不同评估指标,如PPL适用于语言建模,ROUGE适用于摘要,Pass@k适用于代码生成。
人工评估仍是“金标准”,但成本较高。
未来趋势:综合性评估,如HELM、MMLU等,以更全面衡量LLM能力。